Key Impact
- •22,000+ hours saved annually
- •98%+ extraction accuracy on complex documents
- •Follow-up rate reduced from 80% to near zero
- •Client satisfaction jumped from 82% to 100%
The Problem
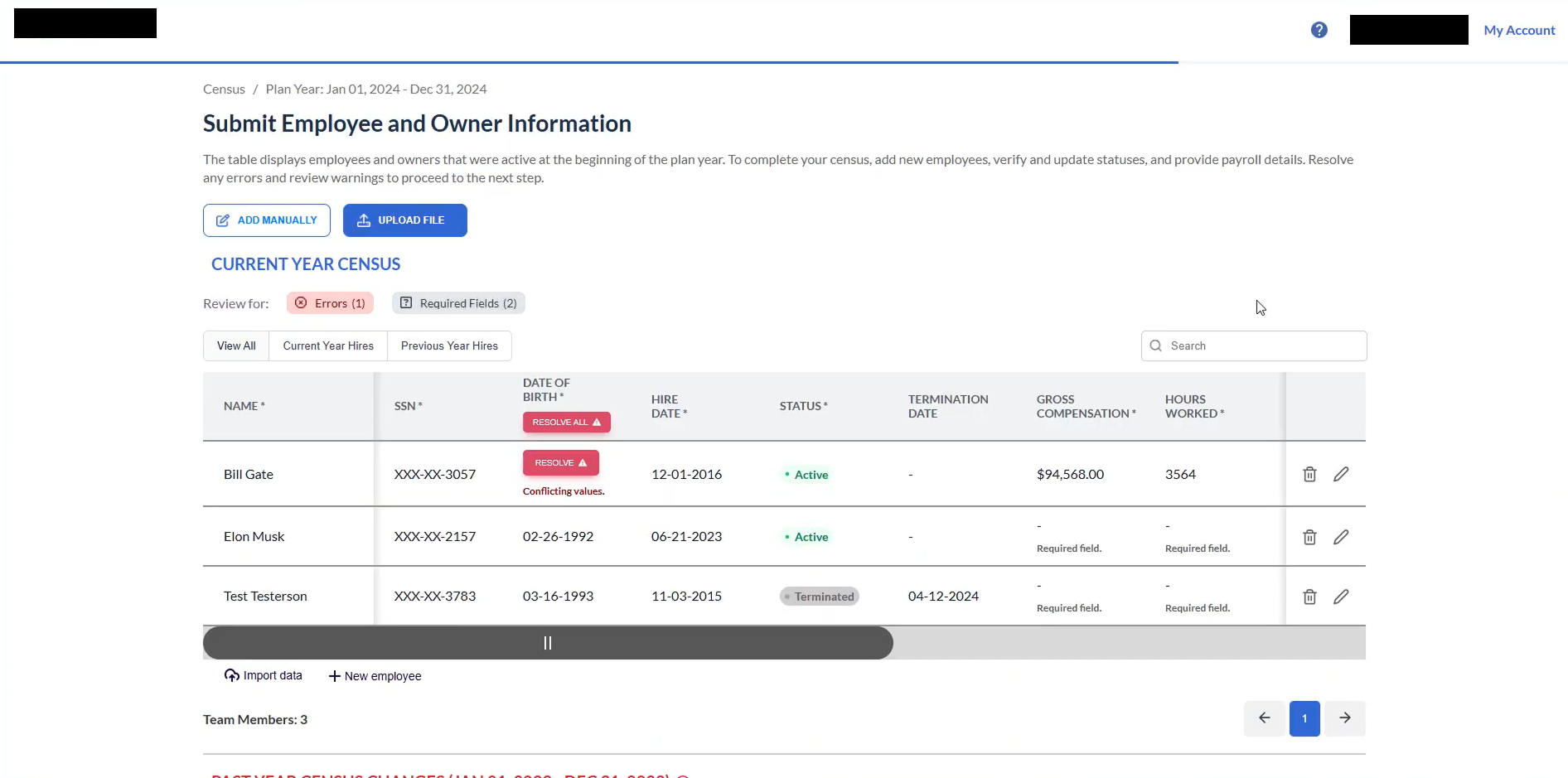
The client, a financial services firm, processed thousands of payroll documents monthly to support their 401k administration services. Each document required manual data extraction: payroll reports, contribution schedules, census files, and more.
The documents came in every format imaginable:
- PDFs ranging from 20 to 100+ pages
- Excel files with inconsistent layouts
- Scanned documents with variable quality
- Different payroll providers with unique formats
The Solution
I built an intelligent document processing portal that automates the entire extraction workflow.
How It Works
1. Document Upload & Classification
Users upload documents through a clean web interface. The system automatically classifies document types and routes them to the appropriate extraction pipeline.
2. AI-Powered Extraction
Using GPT-4's vision and language capabilities, the system extracts structured data from complex, multi-page documents. The model understands payroll semantics. It knows what a contribution rate looks like, how to handle employer matches, and when numbers don't add up.
3. Validation & Review
Extracted data goes through automated validation rules before human review. The interface highlights confidence scores and flags potential issues, so reviewers focus attention where it matters.
4. Export & Integration
Clean, validated data exports directly to the client's downstream systems in their required format.
Technical Approach
The challenge wasn't just OCR. It was understanding. Payroll documents have implicit structure that requires reasoning to parse correctly.
Key Technical Decisions:
- Vision + Language Model: Used GPT-4's multimodal capabilities to handle both scanned PDFs and native digital documents
- Structured Output: Implemented strict schema enforcement to ensure extracted data matches expected formats
- Confidence Scoring: Built calibrated confidence scores so reviewers know when to trust extraction vs. when to verify
- Serverless Architecture: Azure Functions for cost-effective, scalable processing of variable workloads
- Audit Trail: Complete logging of all extractions and edits for compliance requirements
Handling Edge Cases
Payroll documents are messy. We built specific handling for:
- Multi-employer documents with interleaved data
- Documents with handwritten annotations
- Inconsistent date formats across providers
- Missing or ambiguous field labels
- Tables that span multiple pages
Results
The impact was immediate and measurable:
- 22,000+ hours saved annually in manual data entry
- 98%+ extraction accuracy across all document types
- Follow-up rate dropped from 80% to near zero because data is right the first time
- Client satisfaction jumped from 82% to 100%